Beschreibung
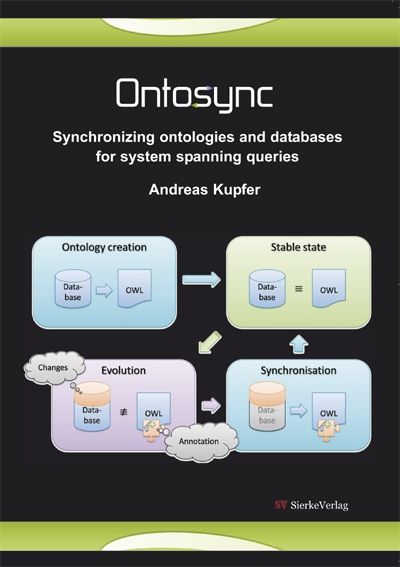
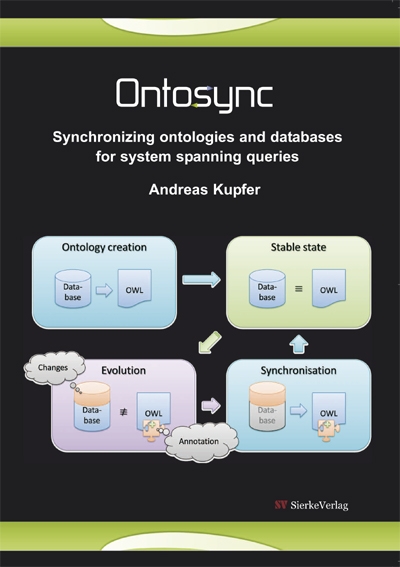
Integrating information from different sources has been a challenge for the database community for decades. The perfect solution is still out of reach, but various improvements can be made. This thesis will present a solution by using an ontology-based integration approach removing an often-cited drawback, by providing a synchronization method for schema changes. The approach is embedded in a complete system. Starting by the automated construction of the abstraction layer, it also provides visual assistance in the annotation process. System-spanning queries are generated automatically from the framework and distributed in parallel to the annotated databases. The system has been build for and tested with biological databases, but can be used on any kind of distributed heterogeneous databases. The presented method is extensible and flexible. The semantic and syntactic descriptions can be built and extended while the systems are running. The ontologies are optimized for queries and feature a very low computational complexity. All system components are widely compatible by relying solely on W3C Semantic Web standards like OWL and SPARQL and supporting a wide range of SQL dialects.





